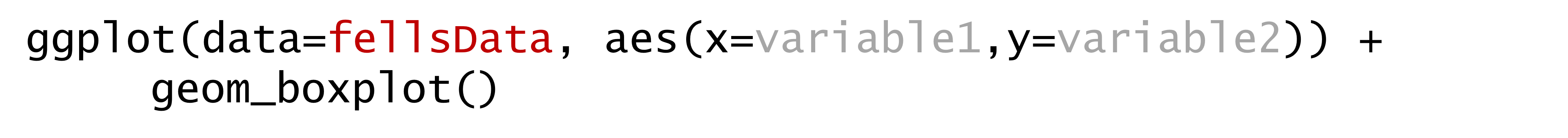Create a file system for this week and add a new Quarto document for today’s lecture.
Download the GSS.csv dataset and load it into R as a tibble
Have a look at sparts and income16 variables: what might these different values represent?
Go to the links on Canvas and take a look at the metadata for each variable. Can you think of a way to modify the data to get a meaningful plot out of it?
The process of data entry is often designed and conducted with limited consideration given to the process of data analysis.
https://openscapes.org/blog/2020-10-12-tidy-data/
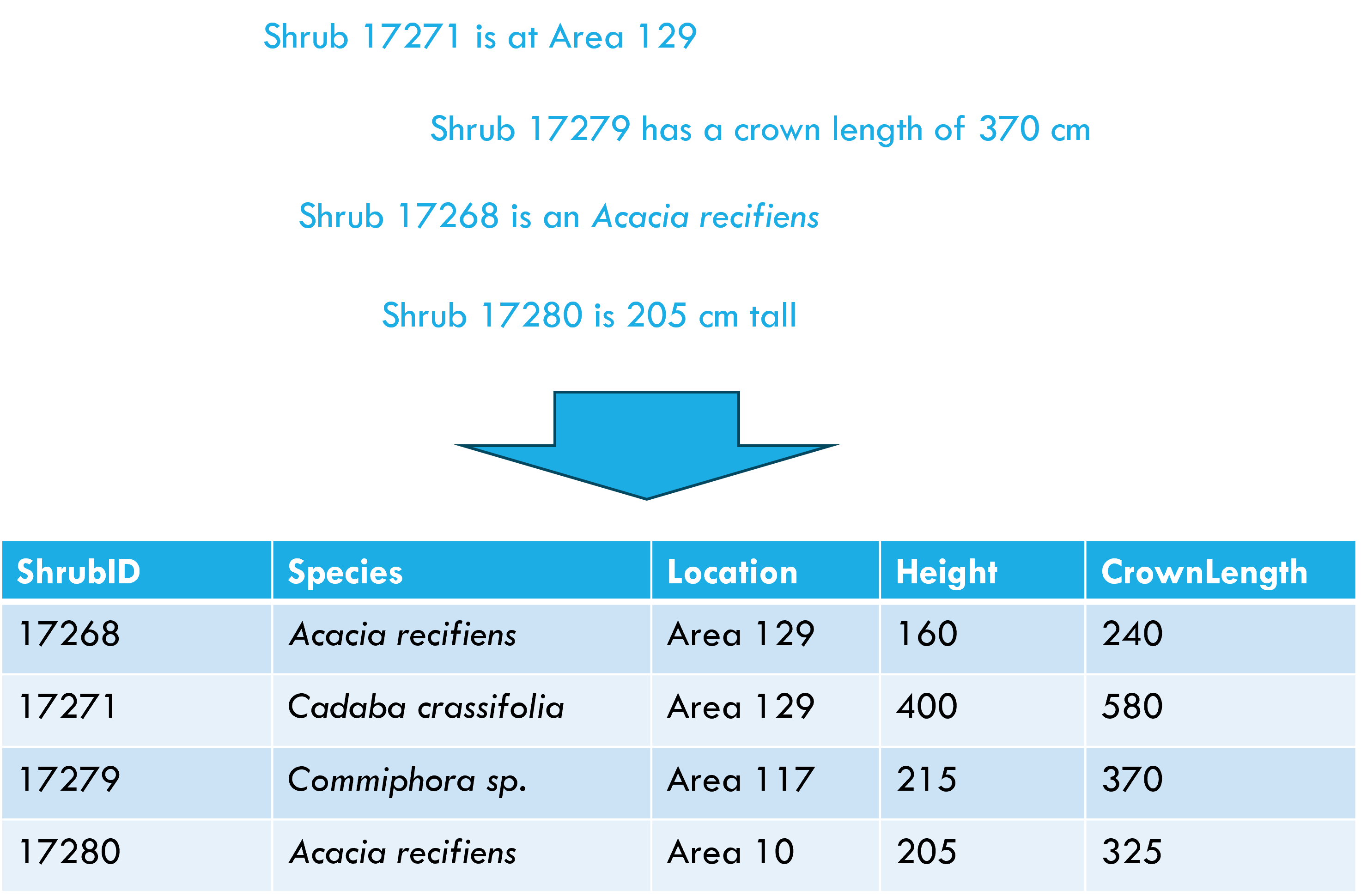
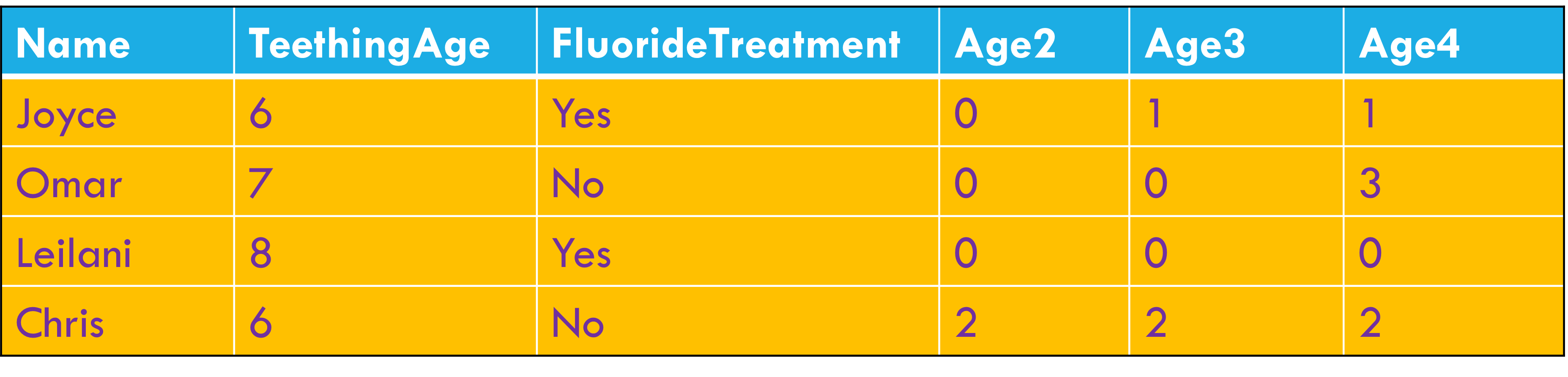
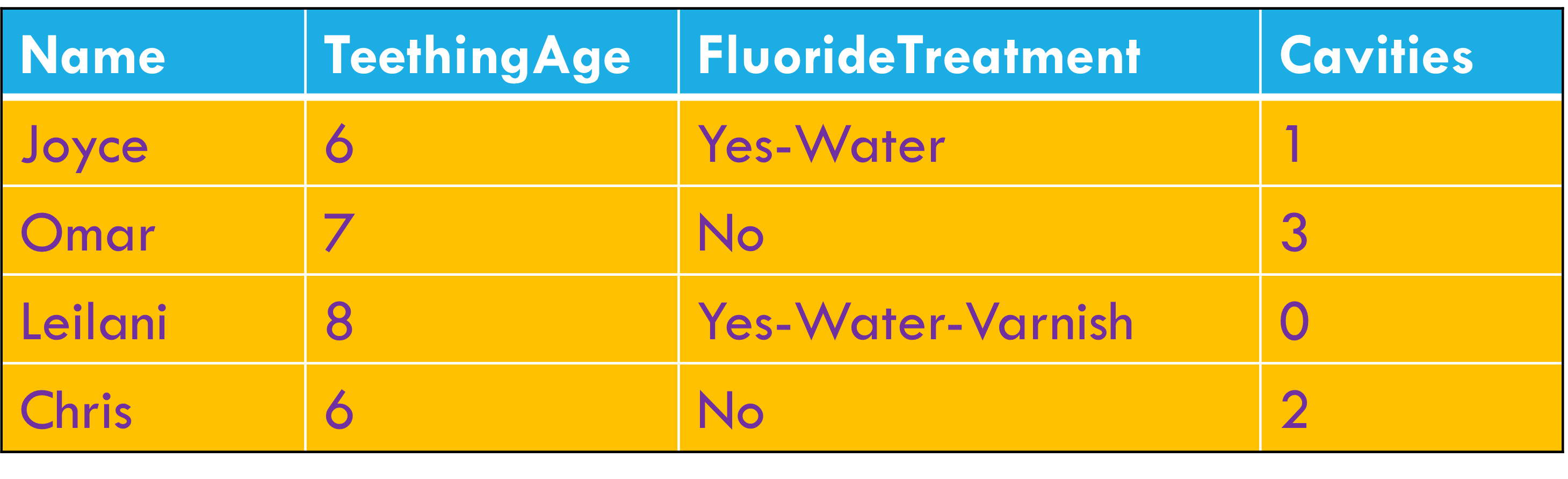
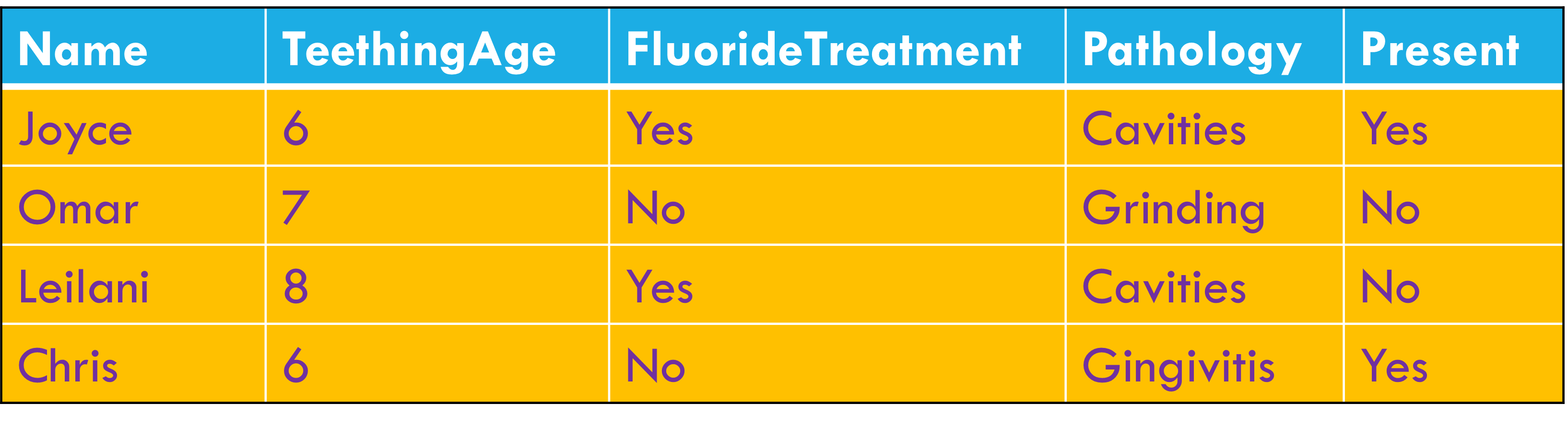
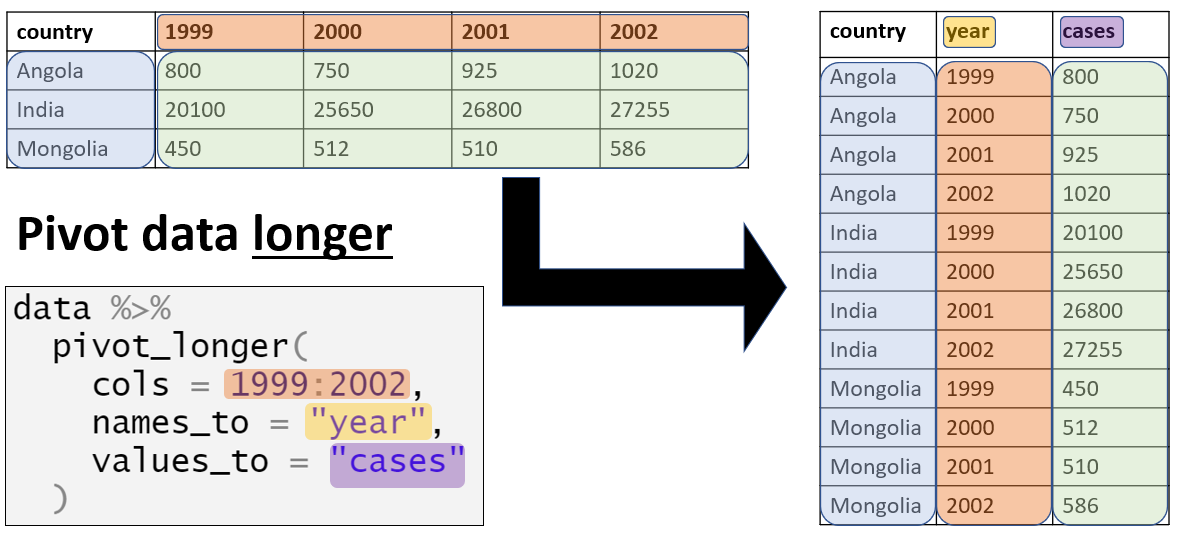
Tidy data principles
Each variable forms a column
Each observation forms a row
Each cell contains a single value
After Wickham, H. 2014. Tidy data. The Journal of Statistical Software 59.
Vectorization
Querying
Consistency
Ease of identification and re-use
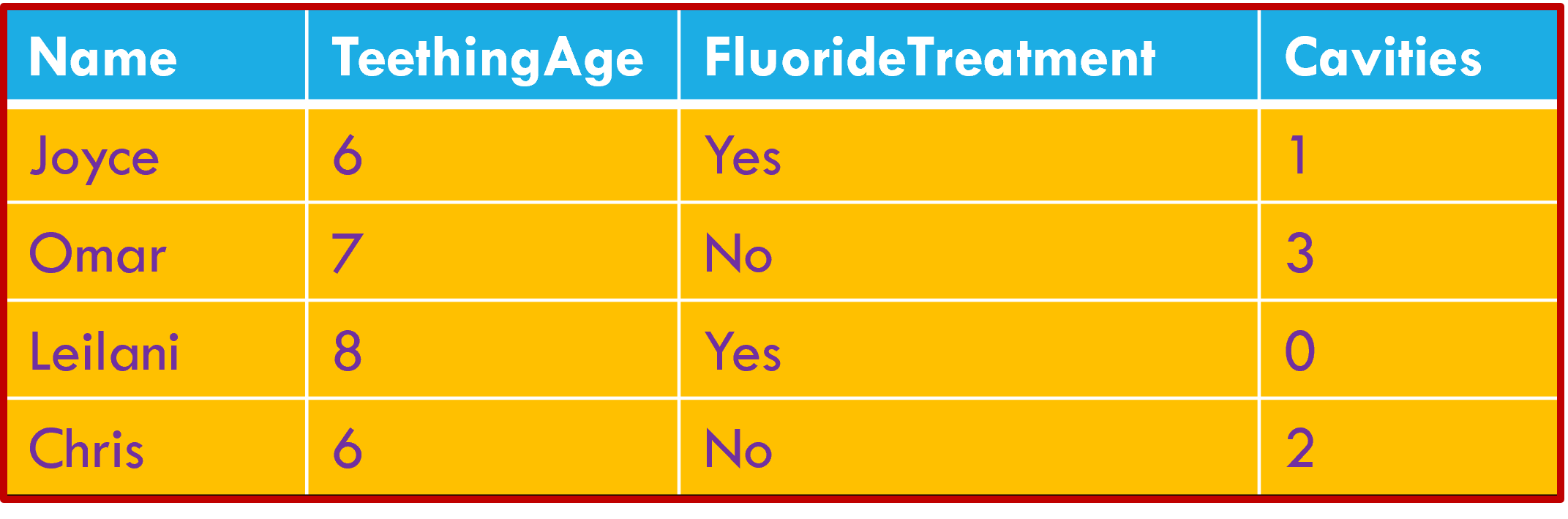
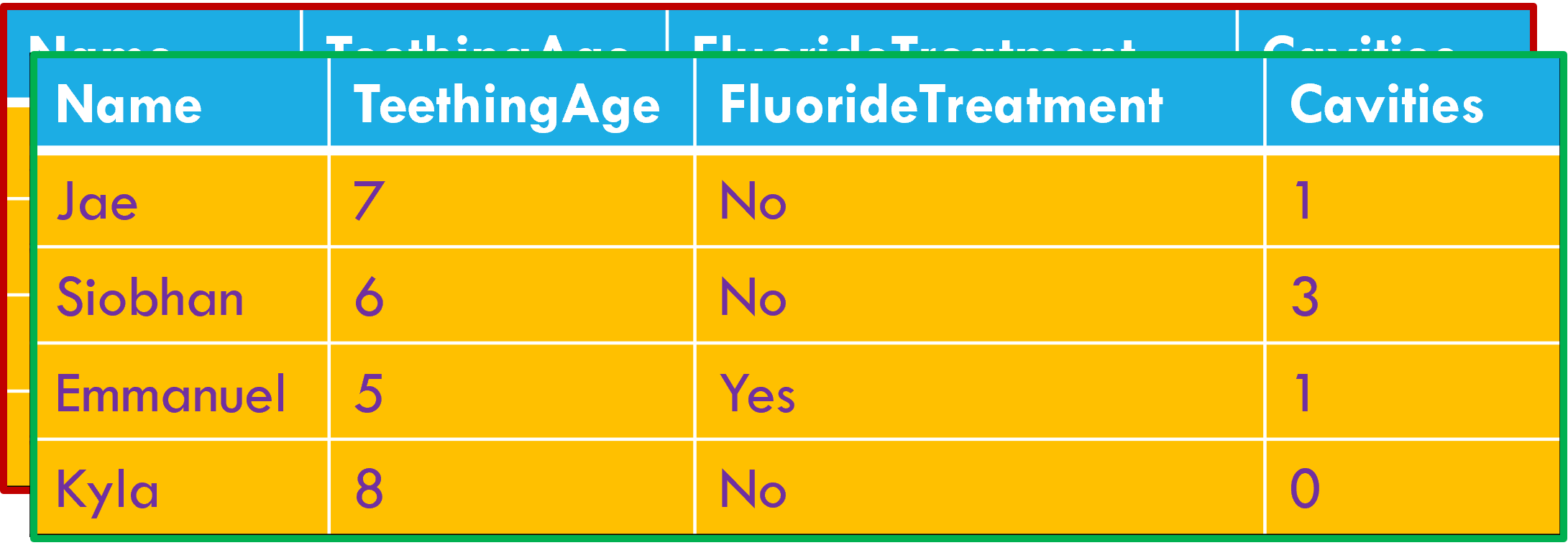
Activity: Making a mess of data
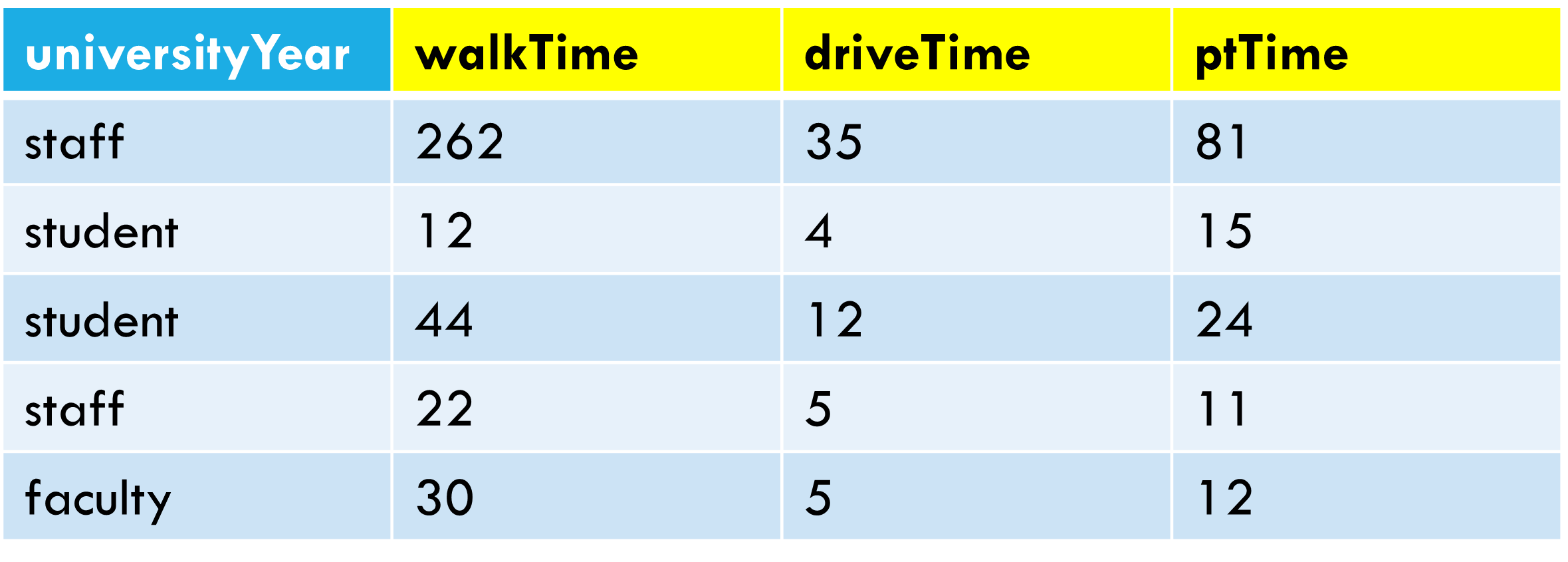
With the sticky notes you’ve been given, complete the data table that’s been started on the door to the data lab. Use Google Maps or similar to estimate transportation times.
friendsofthefells.org
Exploring the data
Compare university year to drive time.
Exploring the data
Compare university year to drive time.
Exploring the data
Compare university year to drive time.
Exploring the survey data
Compare university year to public transit time.
Exploring the survey data
Compare university year to public transit time.
Exploring the survey data
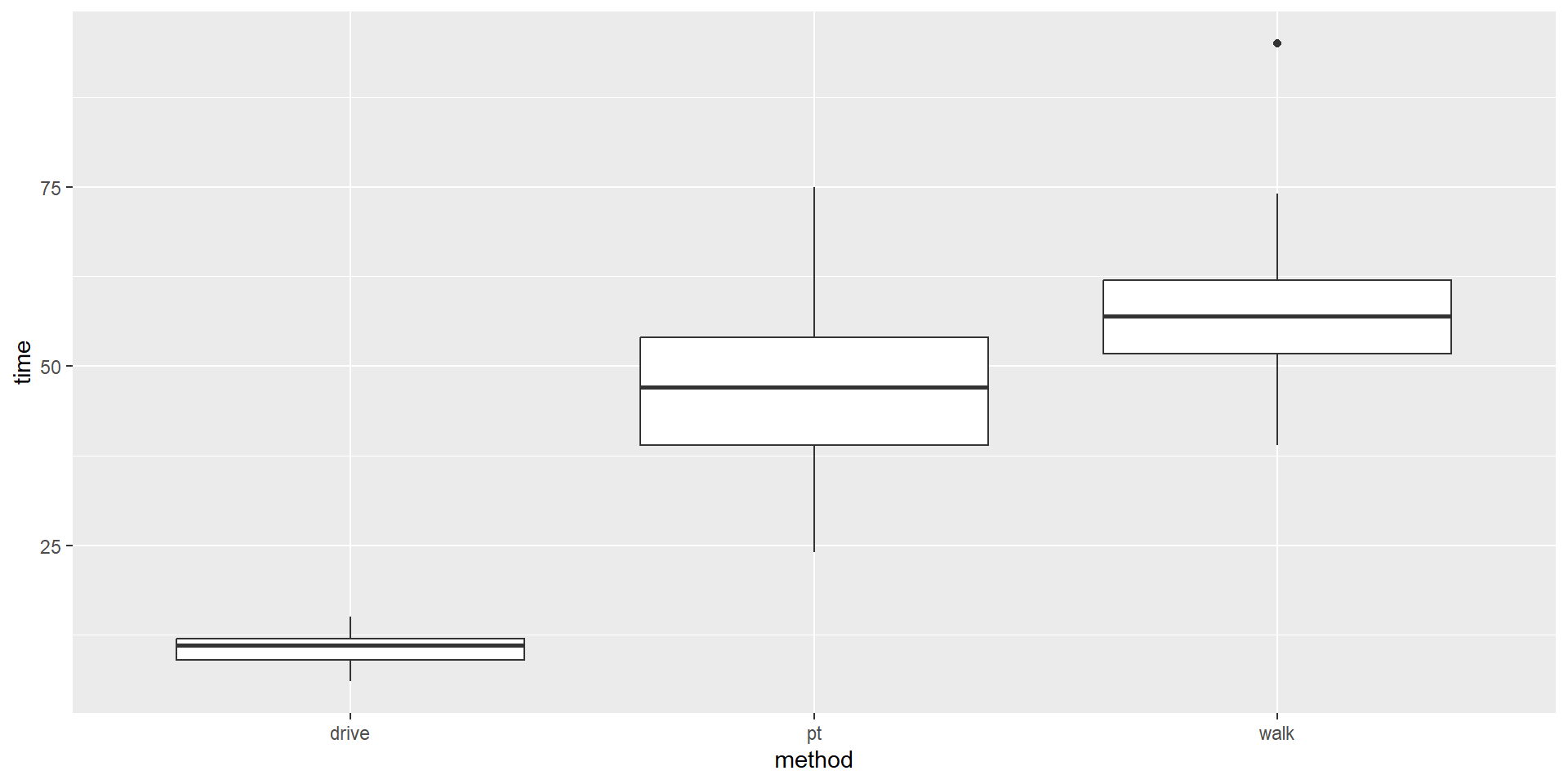
Compare mode of transportation to time spent in transit.
Exploring the survey data
Compare mode of transportation to time spent in transit.
# A tibble: 192 × 3
universityYear method time
<chr> <chr> <dbl>
1 first walkTime 65
2 first driveTime 12
3 first ptTime 37
4 first walkTime 60
5 first driveTime 12
6 first ptTime 51
7 first walkTime 66
8 first driveTime 10
9 first ptTime 33
10 first walkTime 58
# ℹ 182 more rows
# A tibble: 192 × 3
universityYear method time
<chr> <chr> <dbl>
1 first walk 65
2 first drive 12
3 first pt 37
4 first walk 60
5 first drive 12
6 first pt 51
7 first walk 66
8 first drive 10
9 first pt 33
10 first walk 58
# ℹ 182 more rows