Our work on Charlotte’s Willow oaks and squirrel populations caught the attention of conservation groups in South Carolina. They’d like to try and apply our model as a means of estimating tree heights in Charleston. So the question this time is: can our model, developed to estimate tree heights in Charlotte, be used to reliably estimate tree height in Charleston?
charlestoncvb.com
What we are asking our model to do here is predict the heights of trees we have not measured. Our model, which is based on a a linear relationship to our predictor variables, can provide us with estimates of tree heights for any set of values for our predictor variables, so it could be used to do this.
Immediately, though, we should be asking ourselves about how well our model is likely to perform, particularly since we are in a new place. Are there local conditions that might introduce systematic bias? For example, would differences in soil conditions affect the growth of trees in Charleston to the extent that it would affect the relationship between crown base height, DBH, and tree height? A sensible thing to do in this case would be to test the model using some Willow oaks in Charleston where the predictor variable data has already been collected and the heights of the trees is known. Luckily, such a dataset exists in our tree inventory!
First, we can subset our data to the appropriate city and species:
Rows: 14487 Columns: 41
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (15): Region, City, Source, Zone, Park/Street, SpCode, ScientificName, C...
dbl (25): DbaseID, cell, Age, DBH (cm), TreeHt (m), CrnBase, CrnHt (m), Cdia...
num (1): TreeID
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Next, we can use the predict function to generate some predicted tree heights for This function takes two arguments
The model from which we are deriving predictions (in this case, treeModel_dbhCb).
A table (tibble/dataframe) that has columns with names that match the predictor variable names from our model. The important thing here is to make sure that the column names are the same between the model and new data, and that these correspond with the same kind of data.
The result is a named vector, where predicted value has a number that corresponds to its row in the observed data. To evaluate our predictions, we need three pieces of information:
Heights from Willow Oaks in Charleston,
The heights predicted for those trees by our model
The differences between them (also termed the residuals)
The residuals are an indicator of model performance: how far off the mark is each prediction from reality? If all the residuals were 0, then there is no difference between our modeled heights and observed heights, so our model would be a perfect prediction. But with most systems of interest in the study of the environment, this is unlikely to occur: natural and social systems are almost never so straightforward. Because tree growth is influenced by a lot of factors, some deviation between model outcomes and reality is expected. But if the goal is to provide accurate predictions of tree height, we want these residuals to be as minimal as possible.
Beyond the overall magnitude of the residuals is their organization. Ideally, we want the distribution of residuals to be normally distributed around a value of 0, which would suggest that any error in our model is due to random variation. If the residuals show some regularity in their difference, like being centered around a value other than 0 or becoming then our model is providing a poor fit to the data.
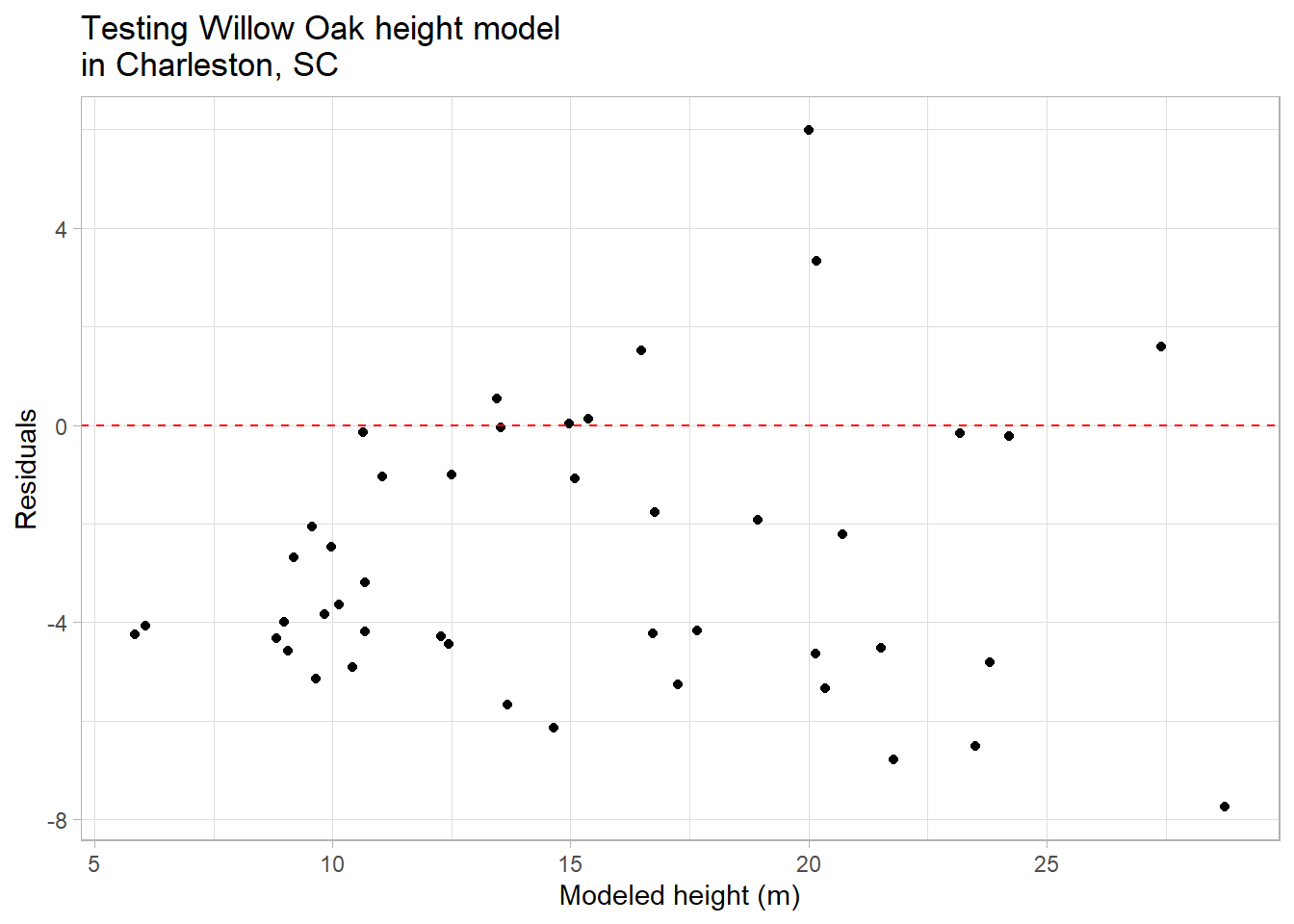
Now let’s take a look at the predictions and their residuals from our prediction of Charleston Willow Oaks.
ggplot(testData,aes(x=modHt_m,y=residuals)) +geom_point() +geom_hline(yintercept=0,color="red",lty=2) +labs(x="Modeled height (m)",y="Residuals",title="Testing Willow Oak height model \nin Charleston, SC") +theme_light()
How do we interpret this graph? We’ve included a red line here to indicate how far off the predictions are from reality. We can see that a good number of them fall within a range of +/- 5 meters. This isn’t terribly accurate, though it would be up to the Charleston conservation group to decide whether this is accurate enough to meet their needs.
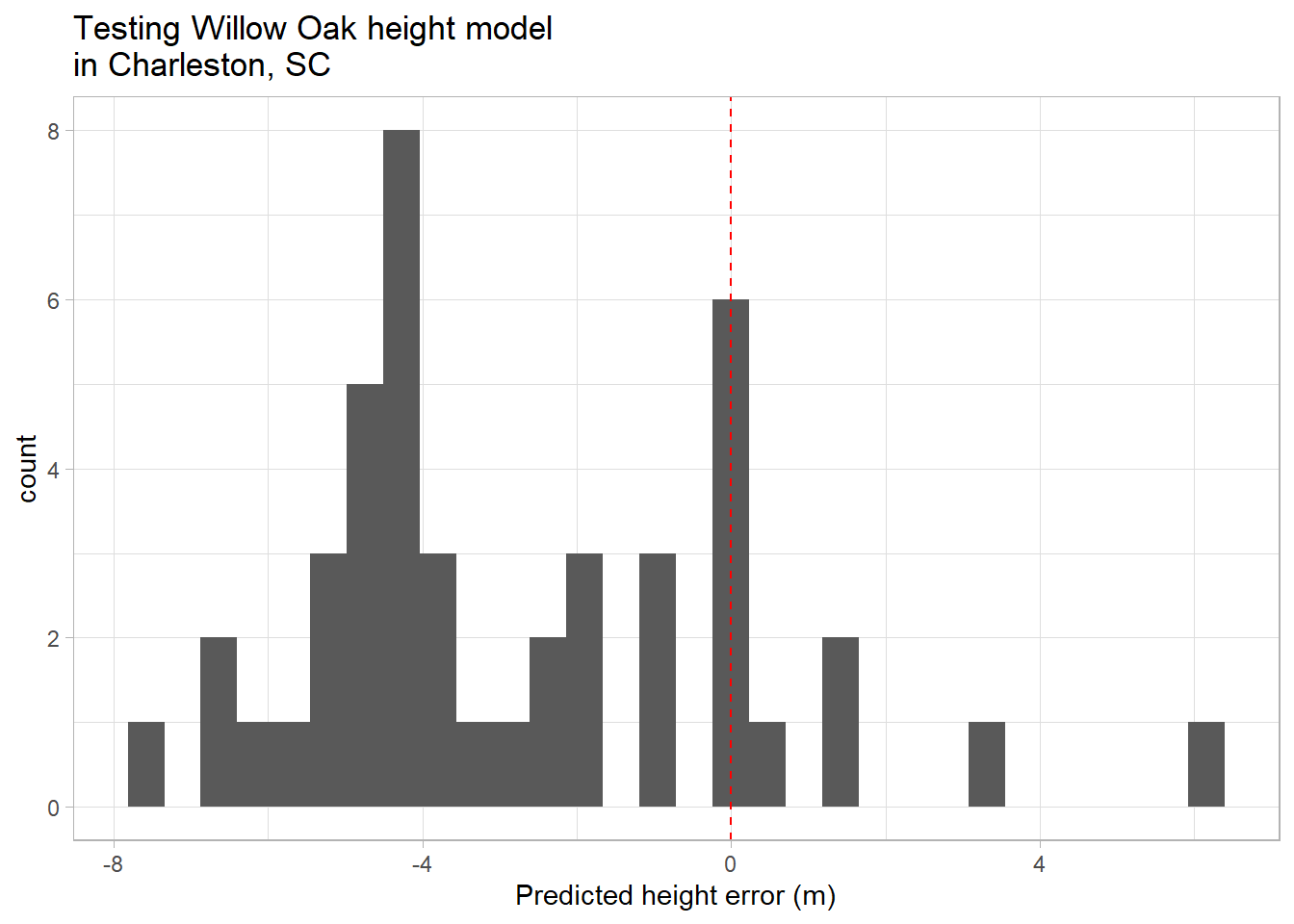
However, there’s another pattern here: the residuals from the modeled heights are systematically lower than 0; only 7 out of 45 residuals has a value above 0. We can also see this by plotting the residuals as a histogram:
ggplot(testData,aes(x=residuals)) +geom_histogram() +geom_vline(xintercept=0,color="red",lty=2) +labs(x="Predicted height error (m)",title="Testing Willow Oak height model \nin Charleston, SC") +theme_light()
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Because our residuals are derived from subtracting the modeled (predicted) heights from the observed heights, negative values would indicate that modeled values are higher than the observed. This suggests that our model, based on the relationship between tree attributes in Charlotte, is systematically overestimating the heights of trees in Charleston.
It’s not clear why this might be the case. It could be a function of the data collection process, whereby something about the way the data was collected differed in a meaningful way. For example, the trees in Charleston may have been concentrated in one part of town, while those from Charlotte were not. In a worst-case scenario, the recording of data may have performed incorrectly in one or bother of these places, resulting in a systematic difference.
But assuming the data on these variables was recorded in a consistent way between these two locations, we might look to environmental differences between these two locations for an explanation. Latitude, temperature, rainfall, soil nutrients: any of these might be different between these two locations. More data, more analysis, or both may help clarify the picture. But in the meantime, to get more accurate estimates of tree heights, our friends in Charleston will likely want to develop their own model using local data.
Try it yourself!
Don’t leave Charleston hanging! Can you use the process in the previous sections to develop a model based on Willow oak trees there?
3.0.1 Going further
This really only scratches the surface when it comes to modeling with data. Linear models are very useful, but also limited because many relationships are not linear. For example, think about the relationship between how long it would take to clean your house and the number of people helping. At lower numbers of people, the amount of time is likely to decrease as you have more assistance; but after a certain point, the house becomes too crowded, and the presence of so many people will create more mess than you can keep up with.
One thing to keep an eye out for is instances where the response variable is not continuously distributed across the predictor values. For example, if you have a binary response variable (0 or 1), it is not possible to consider this continuously distributed. The Generalized Linear Model can be accessed using the glm function, and allows you to specify a distribution other than normal in your assessment of the data.
If you’re interested in looking into doing more complex modeling, there are a number of resources out there. Here are a couple to get you started:
There is an excellent section on regression in YaRrr! The Pirate’s Guide to R by Nathaniel Phillips, including sections on interactions between predictor variables, and on using the Generalized Linear Model.
If you’re interested in doing more complex modeling and integrating modeling within the tidyverse workflow, I highly recommend Tidy Modeling with R by Max Kuhn and Julia Silge. The functions take on a very different structure, but once mastered can be very powerful for modeling data.