In class, we will be discussing the principles of tidy data. These are:
each variable is stored in its own column
each observation is stored in its own row
each cell contains a unique value
These seem pretty straightforward, but in fact these simple rules are broken quite regularly, with data stored in column names, or multiple data types stored in a single column, or variables stored in both rows and columns. The tidyr package provides some key functions for dealing with these kinds of issues.
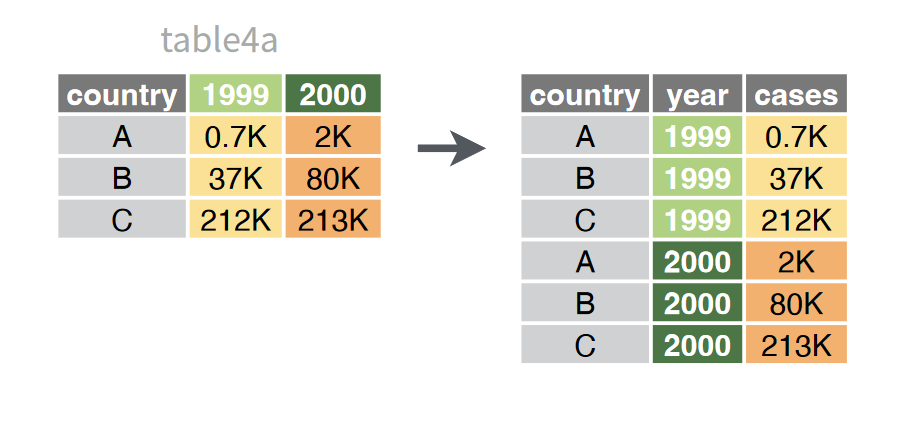
Oftentimes, categorical information you want to use is actually stored in the names of columns. To deal with this, we can gather the data in these columns into two columns: one with the column names, and another with their associated values.
In the tree dataset, for example, the last 8 columns are values for DBH recorded across multiple stems (up to 8). Not every tree will have these, so the table uses -1 to indicate an absence of stems. We can use pivot_longer to turn each of these columns into a value in a single column:
Here’s a breakdown of the arguments being used here:
data is the table being pivoted (in this case, treeData)
cols is the columns where the names are going to be converted to data (in this case, columns dbh1 to dbh8 (you could substitute a vector of columns names if they aren’t in sequential order)
names_to provides a name for a new column where the names are going to be stored as a data
values_to provides a name for a new column where the values from the columns we are converting will go.
Running this code, you can see the effect. While we’re at it, we might want to eliminate the letters “dbh” from the stem number values. We can do this by adding an additional argument: names_prefix.
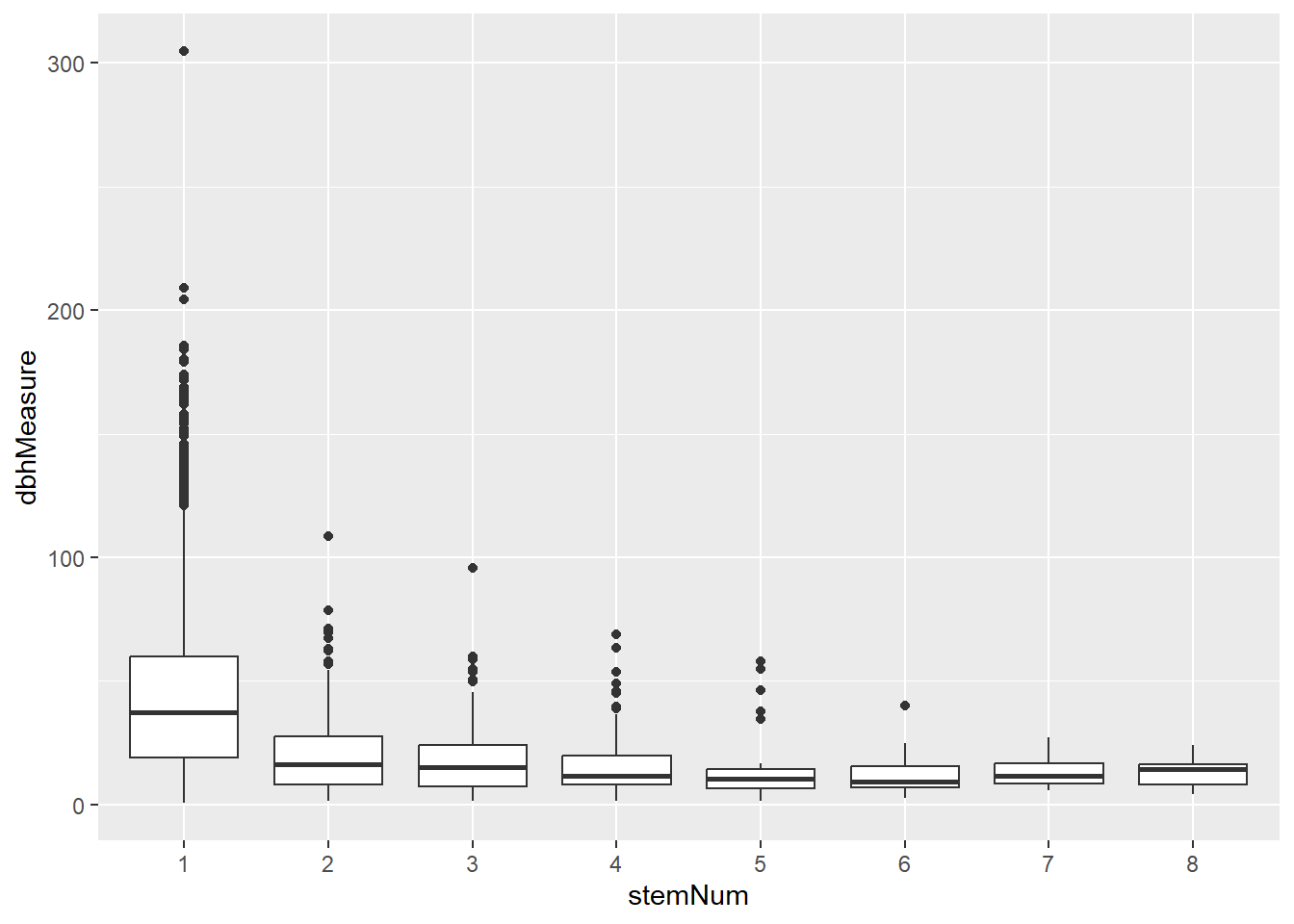
What this data allows us to do more easily is use stem number itself as a variable. For example, we can now plot a boxplot to show how these vary in terms of DBH measurements:
The seperate function takes columns where there is more than one piece of information and breaks it up into multiple columns. For example, let’s say we wanted separate columns for the genus and species of the trees:
The arguments here should look familiar, but a couple may be worth discussing. The sep argument gives the symbol that separates the two sections. Here, the genus and species are separated by a single space, so we include that in quotes. The extra argument gives instructions on what to do with any extra data. If you look at the original tree data, you can see some scientific names have more than two parts. In this case, let’s assume we’re not too fussy about that, so we use the argument “drop” to get rid of it.
3.0.4 Unite
Unite is the opposite of separate. It simply takes two columns and puts them together, like so: